The Geolocation API is built into all modern mobile browsers and it lets you take either a quick, onetime snapshot, or you can get continuous location updates. Using the browser to get your approximate location is very, very cool, but it’s also fraught with many challenges. The vast majority of blog posts on this API talk about what it can do, this blog post focuses on how to best use it and understanding the data provided by the API.
To start things out, let’s take a quick look at a short list of some of the challenges when using the Geolocation API.
Challenge 1. You will not know where the location information is coming from. There’s no way to tell if it’s from the GPS, the cellular provider or the browser vendors location service. If you care about these things then the native Android SDK, for example, gives you a huge amount of control over what they call ‘location providers.’
Challenge 2. You cannot force the app to stay open. This means that the typical user has to keep tapping the app to keep it alive otherwise the screen will go to sleep and minimize your app.
Challenge 3. Speaking about minimizing apps, when the browser is minimized the geolocation capabilities stop working. If you have a requirement for the app to keep working in the background then you’ll need to go native.
Challenge 4. You’ll have very limited control over battery usage. Second only to the screen on your phone or tablet, the current generation of GPS chips are major energy hogs and can suck down your battery very quickly. Since the Geolocation API gives you very little control over how it works you cannot build much efficiency into your apps.
Challenge 5. Most smartphones and tablets use a consumer-grade GPS chip and antenna, and that limits the potential accuracy and precision. On average, the best possible accuracy is typically between 3 and 10 meters, or 10 – 33 feet. This is based on my own extensive experience building GPS-based mobile apps and working with many customers who are also using mobile apps. Under the most ideal scenario, the device will be kept stationary in one location until the desired accuracy number is achieved.
What’s it good for? Okay, you may be wondering what is browser-based geolocation good for? It’s perfect for very simple use cases that don’t require much accuracy. If you need to map manhole covers, or parking spaces, or any other physical things that are close together you’ll need a GPS device with professional-level capabilities.
Here are a few generic examples that I think are ideal for HTML5 Geolocation:
- Simply getting your approximate location in latitude/longitude and converting it to a physical address.
- Finding an approximate starting location for searching nearby places or things in a database or for getting one-time driving directions.
- Determining which zip code, city or State you are in to enable specific features in the app.
- Getting the approximate location of a decently sized geological feature such as a park, a building, a pond, a parking lot, a driveway, a group of trees, an intersection, etc.
What’s the best way to get a single location? The best way to get a single location is to not use getCurrentPosition() but to use watchPosition() and analyze the data for a minimum set of acceptable values.
Why? Because getCurrentPosition() simply forces the browser to barf up the best available raw, location snapshot right now. It literally forces a location out of the phone. Accuracy values can be wildly inaccurate, especially if the GPS hasn’t warmed up, or if you aren’t near a WiFi with your WiFi turned on, or if your cellular provider can’t get a good triangulation fix on your phone, or it returns a cached value from a different location altogether. There are many, many “what ifs?”
So, I recommend using watchPosition() and firing it off and letting it run until the return values meet some minimum criteria that you set. You need to know that while this is happening the location values returned may cover a fairly wide geographic area…remember our best accuracy values are 10 – 30 meters. Here’s a real-world example of Geolocation API location values that I captured over a 5 minute period while standing stationary in front of a building.
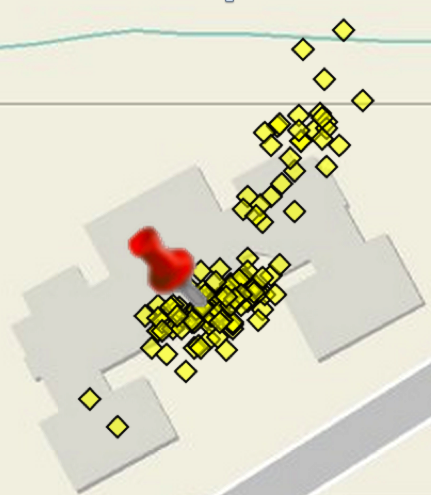
What steps do you recommend? Here are five basic steps to help guide you towards one approach for getting the best location. This is a very simplistic approach and may not be appropriate for all use cases, but I think it’s adequate to demonstrate the basic concepts for working towards determining the best possible location.
Step 1. Immediately reject any values that have accuracy above a certain threshold that you determine. For example, let’s say we’ll reject any values with an accuracy reading greater than 50 meters.
Step 2. Create three arrays, one for accuracy, latitude and longitude. If the accuracy is below your threshold, or in this case < 50 meters, then push the values to the appropriate arrays. You will also need to set a maximize size for the array and create a simple algorithm for adding new values and removing old ones.
The array length could be 10, 20 or even 100 or more entries. Just keep in mind that the longer the array, the longer it will take to fill up and the longer the user will have to wait for the end result.
Step 3. Start calculating the average values for accuracy, latitude and longitude.
Step 4. Start calculating the standard deviation for accuracy, latitude and longitude.
Step 5. If your arrays fill up to the desired length and the average accuracy meets your best-possible criteria, and the standard deviation is acceptable then you can take the average latitude, longitude values as your approximate location.
For an example of this simple algorithm at work visit the following URL on your phone and step outside to get a clear view of the sky: https://esri.github.io/html5-geolocation-tool-js/field-location-template.html. [Updated link: Oct. 27, 2015]